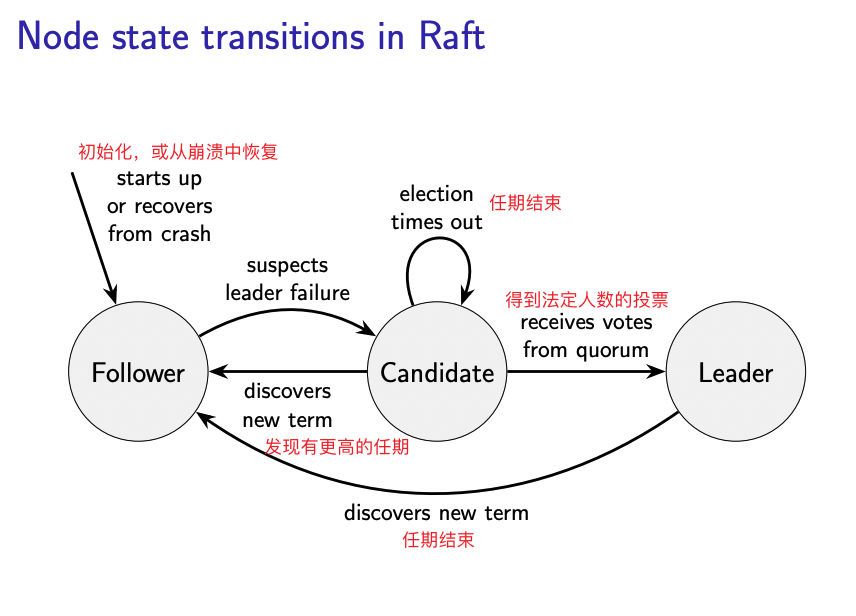
on initialisation do currentTerm := 0; votedFor := null //term在每次选举之后+1, log := <>; commitLength := 0 //log是entry的序列,每一条entry包含我们要发送的信息和当前的term //log末尾增加,并通过raft将其复制到所有节点,当log的条目被复制到法定人数则确认 //确认的log无法再更改,所有在commit length之前的log都是固定了的 //上面的变量存储在磁盘中,为了错误恢复 //每当有更新,必须先写入磁盘,再做其他的事情 currentRole := follower; currentLeader := null votesReceived := {}; sentLength := <>; ackedLength := <> //这些变量可以在易失性存储器上,如RAM end on
on recovery from crash do currentRole := follower; currentLeader := null votesReceived := {}; sentLength := hi; ackedLength := hi //从崩溃中恢复,恢复上面易失的变量 end on
on node nodeId suspects leader has failed, or on election timeout do //当节点怀疑leader崩溃,或者到达任期之后 currentTerm := currentTerm + 1; currentRole := candidate //节点任期 + 1,成为候选人 votedFor := nodeId; votesReceived := {nodeId}; lastTerm := 0 //节点为自己投票 if log.length > 0 then lastTerm := log[log.length − 1].term end if //lastTerm变量设置为log中最后一条记录的任期 msg := (VoteRequest, nodeId, currentTerm, log.length, lastTerm) //msg类型为voteRequest,节点的ID,节点的任期,log的长度,lastTerm for each node ∈ nodes: send msg to node //发送给每一个节点 start election timer //开启计时器,如果没有收到足够的选票,重启选举 end on
on receiving(VoteResponse, voterId, term, granted) at nodeId do //如果自己不是候选人则什么都不做 if currentRole = candidate && term = currentTerm && granted then //确认选票是投给自己这一次选举,且是支持票,如果投的票term小于currentTrem直接忽略 votesReceived := votesReceived ∪ {voterId} //加入收到的选票集合,注意是集合并操作,故具有幂等性 if |votesReceived| ≥ d(|nodes| + 1)/2e then //每次都判断是否得到了法定人数的选票 currentRole := leader; currentLeader := nodeId cancel election timer //修改自身为leader,停止计时器 for each follower ∈ nodes \ {nodeId} do sentLength[follower ] := log.length ackedLength[follower ] := 0 //sL以及aL将每一个节点Id映射到一个整数上,分别代表多少msg被发送给了节点, //以及节点到现在确认了多少msg,这些都是假设有可能会出错 ReplicateLog(nodeId, follower) //告诉所有节点自己现在是leader end for end if elseif term > currentTerm then //如果得到的选票的任期大于候选人自己的任期,让出选举权,变成follower currentTerm := term currentRole := follower votedFor := null cancel election timer end if end on
on request to broadcast msg at node nodeId do //leader广播的操作,首先判断是不是leader if currentRole = leader then append the record (msg : msg, term : currentTerm) to log //将msg以及当前任期加入log ackedLength[nodeId] := log.length //leader自己确认log for each follower ∈ nodes \ {nodeId} do //出了leader的每个节点 ReplicateLog(nodeId, follower ) //复制新的entry到follower end for else //如果不是leader,将消息通过FIFO链路转发到leader forward the request to currentLeader via a FIFO link end if end on
periodically at node nodeId do //leader每隔一段时间调用复制log的函数,复制log到每个follower //1.作为心跳告诉follower自己还活着 //2.防止由于网络原因丢失消息,故定期重传 if currentRole = leader then for each follower ∈ nodes \ {nodeId} do ReplicateLog(nodeId, follower ) end for end if end do
5/9 函数ReplicateLog
每当有新msg到达leader,或者定期调用
如果没有新消息,entries是空列表
logRequest消息和空entries作为心跳,让follower知道leader还活着
1 2 3 4 5 6 7 8 9 10 11 12 13
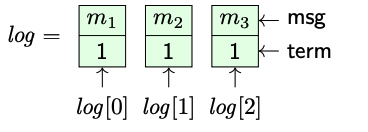
function ReplicateLog(leaderId, followerId) prefixLen := sentLength[followerId] //得到现在已经发送给这个follower的log长度 suffix := <log[prefixLen], log[prefixLen + 1], . . . ,log[log.length − 1]> //得到所有现在还没有发送给follower的log prefixTerm := 0 if prefixLen > 0 then prefixTerm := log[prefixLen − 1].term //发送的msg附带了之前发送给follower节点中最后一个entry的任期信息,用于一致性检查 end if send (LogRequest, leaderId, currentTerm, prefixLen, prefixTerm, commitLength, suffix ) to followerId end function
function AppendEntries(prefixLen, leaderCommit, suffix ) //leadercommit为leader的commit长度 if suffix .length > 0 && log.length > prefixLen then //如果leader发过来的entries长度大于0,并且节点log的长度大于leader发来的leader的发送长度 //如果term不同意味着需要舍去本地多余的记录(可能来自老leader未被确认的部分) //△△△term相同意味着可能node的ack丢失了 index :=min(log.length, prefixLen + suffix .length) − 1 //得到最小需要更新的index if log[index ].term != suffix [index − prefixLen].term then log := <log[0], log[1], . . . , log[prefixLen − 1]> end if //比较能得到的本地log最后的term和leader发过来的term //如果不一致则丢弃本地的,用leader发来的覆盖 end if //下面进行append操作 if prefixLen + suffix .length > log.length then for i := log.length − prefixLen to suffix .length − 1do append suffix [i] to log end for end if //下面进行commit操作 if leaderCommit > commitLength then for i := commitLength to leaderCommit − 1do deliver log[i].msg to the application //将已经提交的log发送给上层应用 end for commitLength := leaderCommit end if end function
on receiving(LogResponse, follower , term, ack, success) at nodeId do if term = currentTerm ∧ currentRole = leader then //term相等且自己是leader if success = true ∧ ack ≥ ackedLength[follower ] then sentLength[follower] := ack ackedLength[follower] := ack //一切正常,两个都置为ack CommitLogEntries() elseif sentLength[follower] > 0 then //follower出现了gap,需要fill sentLength[follower] := sentLength[follower ] − 1 ReplicateLog(nodeId, follower ) //回退一个entry,suffix+1长度之后重试 end if elseif term > currentTerm then //出现了更大的term,自己变成了follower currentTerm := term currentRole := follower votedFor := null cancel election timer //变成follower的操作 end if end on
9/9 leader提交log entries
任何被法定人数节点确认的log entries需要被leader提交
每当log entry被提交,msg被送给上层应用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
function CommitLogEntries while commitLength < log.length do acks := 0 for each node ∈ {nodes} do if ackedLength[node] > commitLength then acks := acks + 1 end if end for if acks ≥ [(|nodes| + 1)/2] then deliver log[commitLength].msg to the application //被提交的msg交给上层应用 commitLength := commitLength + 1 //commitLength同样也告诉follower节点哪些被commit,可以被提交到上层应用 else break end if end while end function