分布式系统:4.Broadcast protocols and logical time⭐
本文最后更新于:2022年3月15日 中午
4. Broadcast protocols and logical time
问题:分布式系统中如何判断事件发生的先后?为什么时间戳不行?
在分布式系统中,不同的机器的时间可能不一样,这样导致这种方法会产生误差。也许你会说让机器定期进行 NTP 时间同步,但是在一个集群中,不同机器内部时间计算也会产生误差,可能有些机器时间前进的快点,有些机器会慢点,这种现象也叫 Clock Drift(时钟漂移)。
4.1 逻辑时间
- 物理钟:计算多少秒时间流逝了
- 逻辑钟:计算多少时间发生了
Lamport Timestamp
Lamport Timestamp 是一种衡量时间和因果关系的方法。现实生活中,很多程序都有着因果(causality)关系,比如执行完事件 A 后才能执行事件 B。通过逻辑时间,我们可以判断不同事件的因果顺序关系。
Lamport Timestamp 算法的实现遵循以下规则:
- 每一台机器内部都有一个时间戳(Timestamp),初始值为 0。
- 机器执行一个事件(event)之后,该机器的 timestamp + 1。
- 当机器发送信息(message)给另一台机器,它会附带上自己的时间戳,如 <message, timestamp> 。
- 当机器接受到一条 message,它会将本机的 timestamp 和 message 的 timestamp 进行对比,选取大的 timestamp 并 +1。
因果律(如何判断因果关系)⭐
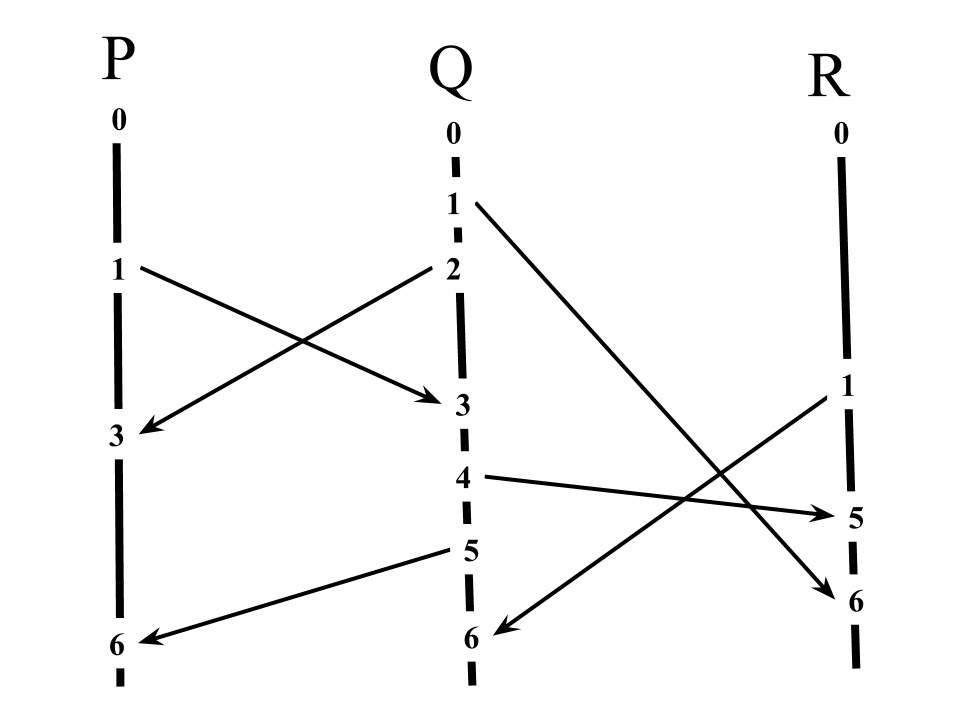
如果事件 A 在事件 B 之前发生,(叫做 happened-before,表示为 A→B),那么事件 A 的时间戳一定小于事件 B。即表达为:$A \rightarrow B \Rightarrow C(A)<C(B)$
但是我们要注意这种推导关系是不能反过来的。$C(A)<C(B)\neq A \rightarrow B$
我们还可以知道,如果$C(A)<=C(B)$,那么事件 B 是绝对不可能发生在事件 A 之前。$C(A)<=C(B) \Rightarrow B \nrightarrow A$
当然,如果事件 A 和 事件 B 的时间戳相同,则它们是并行或独立的,即$C(A) = C(B) \Rightarrow A \nleftrightarrow B$
向量钟⭐
- 背景 但是 Lamport Timestamp 不能很好的满足分布式系统,比如你不能区分两个事件是否有关联,或者在一个多点读的 key-value 数据库中,你无法确定保存哪一份副本(通常保存最新的那份副本)。 如下图所示,你其实无法单纯的通过 logic clock 比较来判断 Process 1 中的事件 3 和 Process 2 中的事件 8 是否有关系。
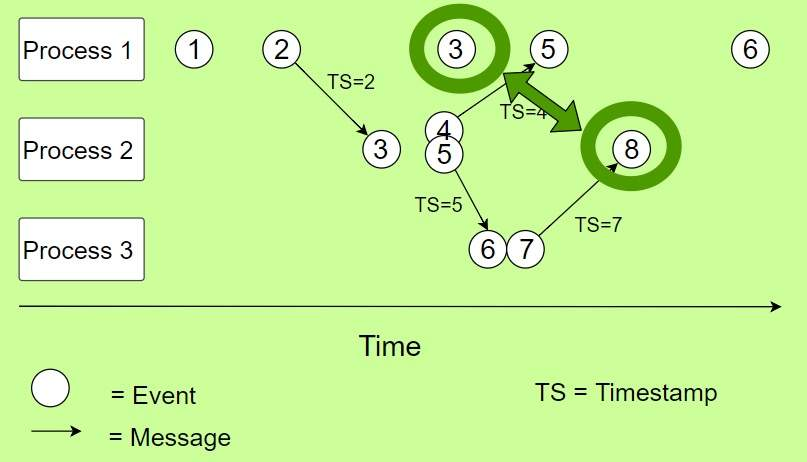 因此引入Vector Clock(向量逻辑时间)
因此引入Vector Clock(向量逻辑时间)
Vector Clock 是通过向量(数组)包含了一组 Logic Clock,里面每一个元素都是一个 Logic Clock。如上图,我们有 3 台机器,那么 Vector Clock 就包含三个元素,每一个元素的索引(index)指向自己机器的索引。我们遵循以下规则:
- 每一台机器都初始化所有的 timestamp 为 0。例如上面的例子,每一台机器初始的 Vector Clock 均为
[0, 0, 0]。 - 当机器处理一个 event,它会在向量中将和自己索引相同的元素的 timestamp + 1。例如 1 号 机器处理了一个 event,那么 1 号机器的 Vector Clock 变为
[1, 0, 0]。 - 每当发送 message 时,它会将向量中自己的 timestamp + 1,并附带在 message 中进行发送。如 <message, vector> 。
- 当一台机器接收到 message 时,它会把自己的 Vector Clock 和 message 中的 Vector Clock 进行逐一对比(每一个 timestamp 逐一对比),并将 timestamp 更新为更大的那个(类似于 Lamport Timestamp 的操作)。然后它会对代表自己的 timestamp + 1。
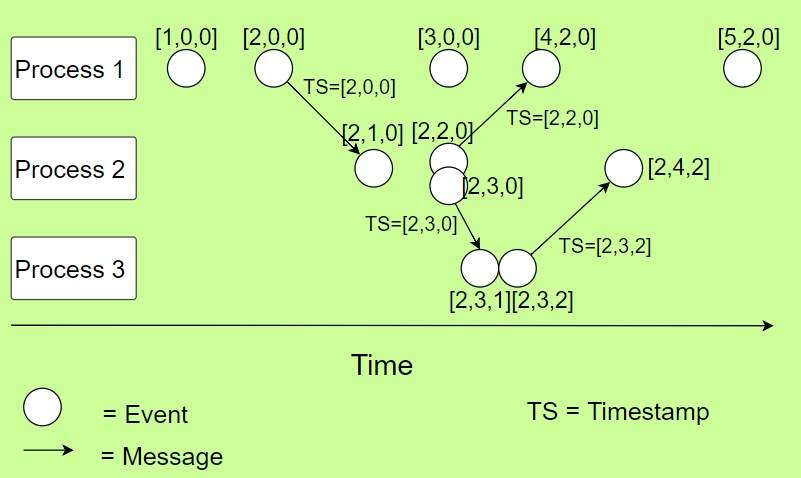
K/V 数据库中的应用
- 举例 传统的分布式数据库存在一个 leader,leader 接收写入请求后,会将写入数据同步到集群一半以上的节点上面。一半以上节点反馈写入成功后,leader 再返回给客户端写入成功,有点类似于 Raft ,是单点写的。 如果我们引入了 Vector Clock,我们可以实现多点写,如 Dynamo 论文中所示。 假设 Key K 有三个副本 k1, k2, k3(目前是一样的),分别位于 M1, M2, M3 三台服务器上面,现在因为某种故障,导致了网络分区,三台机器均不能互相通信,但是每台机器仍然能够和客户端保持通讯。 其中 k1 副本被 client 1 持续更新,k2 副本被 client 2 持续更新。当三台机器之间互相通讯恢复的时候,进行副本同步时,应该保留哪个版本?如果只保留 k2,即采用 last write win 机制,那么同步后,client 1 会发现它写的数据丢了。 这个时候就需要 Vector Clock,更确切的说是 Version Clock(Dynamo 中是这么说的)。 为了处理这种场景,Dynamo 使用 Version Clock 来捕获同一份数据(Object) 的不同版本之间的因果关系(causality)。每个 Object 的每个版本会有一个相关联的 Version Clock , 形如
[(serverA, counter), (serverB, counter),...], 通过检查同一个 Object 不同版本的 Version Clock,可以决定是否可以完全丢弃一个版本,仅保留另外一个版本,还是需要将两个版本进行合并(merge)。如果 Object 的版本 A 的 Version Clock 中的每项(server, counter)在版本 B 的 Version Clock 中都有对应项,并且 counter 小于等于版本 B 中对应项的 counter,那么这个 Object 的版本 A 可以被丢弃,否则需要对两个版本进行 merge。 回到刚才的例子,k1 被更新,Version Clock (注:此处假设 k1/k2/k3 三个副本之前一模一样) 为[(M1, 1), (M2, 0), (M3, 0)],k2 被更新,Version Clock 为[(M1, 0), (M2,1), (M3, 0)],随后 k1 和 k2 网络通了,他们通过比较两个 Version Clock 发现两个 Version Clock 存在冲突,且不存在对方每一项 Logic Clock 小于自己的 Logic Clock,那么就两个版本都保留,当客户端来读 Key=K 的时候,两个版本的数据和对应的 Version Clock 都返回给客户端,由客户端进行冲突合并,客户端进行冲突合并后写入Key K的时候,带着合并后的 Version Clock[(M1, 1), (M2, 1), (M3, 0)]发到M1 和 M2 两台机器,覆盖服务器版本,冲突解决。
Vector Clock 缺陷
系统伸缩(Scale)缺陷
其实 Vector Clock 对资源的伸缩支持并不是很好,因为对于一个 key 来说,随着服务器数量的增加,Vector Clock 中向量的元素也同样增长。假设集群有 1000 台机器,每次传递信息时都要携带这个长度为 1000 的 Vector,这个性能不太好接受。
非唯一缺陷
在正常的系统下面,假设所有的消息都是有序的(即同一台机器发送 消息 1 和 2 到另一台机器,另一台机器也会先接收到消息 1 再接收消息 2)。那么我们可以根据每一台机器的 Vector Clock 来恢复它们之间的计算(computation)关系,也就是每一种计算都有着对应自己独一无二的 Vector Clock。
但是,如果消息不是有序的,消息之间会‘超车‘(overtaking),那么问题就来了,看下图:
https://cdn.inlighting.org/blog/2020-05-02-uJrKNN.png!slim
左右两张图,两种不一样的计算方式,但是最终 p 和 q 上面产生了相同的 Vector Clock。也就是说,相同的 Vector Clock 并不代表唯一的 computation。
https://cdn.inlighting.org/blog/2020-05-02-ugBzFk.png!slim
这张图中,我们可以看看 r 节点中的 j,我们无法判断这个 j 是从 p 那边的 e 传递过来还是 r 自己处理了一个事件,在自己 i 的基础上面 +1 。
解决办法 1
在 Vector Clock 中添加事件类型,例如用内部(internal),发送(send),接收(receive)3 种事件表明 Vector Clock。但是这样的话还是有问题,
https://cdn.inlighting.org/blog/2020-05-02-ajHByN.png!slim
我们标明了 send 和 receive 两种事件,但是结果还是不同的 computation 产生了相同的 Vector Clock。(两个receive超车了)
解决办法 2
将 Vector Clock 改为既包含接收到消息的时间和本地时间。例如下面这个图:
https://cdn.inlighting.org/blog/2020-05-02-ajHByN.png!slim
将左边图改为 h:(<3,0>,<3,1>),i:(<1,0>,<3,2>,j:(<2,0>),<3,3>) ,右边图中变为 h:(<3,0>,<3,1>),i:(<2,0>,<3,2>,j:(<1,0>),<3,3>) 。
通过这种方法,我们能够确定每一种 computation 有着唯一的 Vector Clock。虽然这种会导致 Vector Clock 体积增长了一倍。
当然这种方法也不一定完全需要,因为只要我们能够保证消息发送到达的有序,即不产生消息超车(Overtaking)的情况下,原来的 Vector Clock 也够用了。你可以在发送的消息上面再携带上本机的 timestamp,然后对方接受的时候,根据 timestamp 的先后顺序对消息进行排序(因为就是两个节点,点对点,可以使用这种时间戳的方式),这样就保证了消息不会发生超车。参考 TCP 对消息顺序的控制。
4.2 广播协议
- sending a message是proccess主动做的事
- receiving a message是process被动发生的事
- delivering a message是在receiving a message后主动做的事
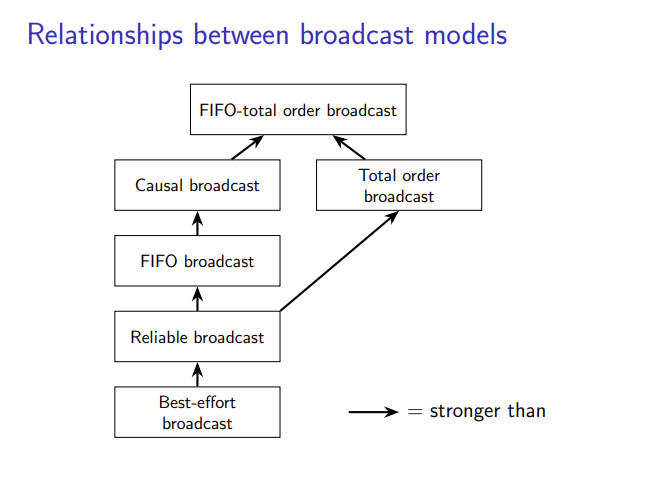
FIFO broadcast
- 最弱的广播类型称为FIFO广播,它与FIFO链接密切相关。在这个模型中,结点收到什么就发送什么,先来先发
Causal broadcast
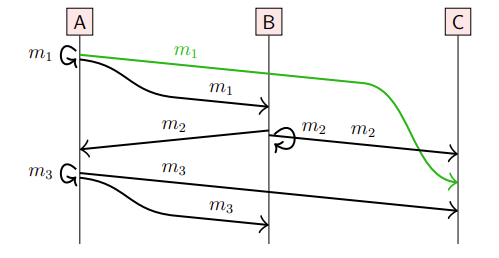
- 因果广播意味着比FIFO广播更强的条件,如果m2 与 m1 有因果关系,那么m2 必须在 m1 之后
- 下图是一个符合FIFO但不符合因果广播的例子,结点C广播m2早于m1
Totally-ordered broadcast
- 第三种类型的广播是全序广播,有时也称为原子广播。
- 虽然FIFO和因果广播允许不同的节点以不同的顺序传递消息,但全序广播加强了节点间的一致性,确保所有节点以相同的方式传递消息
- 总结来说就是:没有因果关系的事件广播顺序可以调换,有因果关系的事件广播顺序所有结点必须相同(因果广播与全序广播并没有关系)
最后引出FIFO全顺序广播,就是套娃
4.3 广播算法的实现
分成两个层次:
- 通过重传丢失的信息,使best-effort的广播服务变成可靠的广播服务
- 在可靠广播的基础上加强广播的顺序
reliable broadcast
最初的想法:最初的发送结点把msg广播给所有与它相连的结点,结束。
问题:有些结点message没收到,发送节点重传的时候宕机了,导致数据不一致
改进:每个结点收到msg之后,广播给所有与它相连的结点
问题:$O(N^2)$复杂度
因此有:Gossip protocols
每个结点收到msg之后,广播给所有与它相连的N个结点,N个结点随机选择
FIFO broadcast algorithm
以下讨论皆在可靠广播的前提下
伪代码:(
- 初始化变量:sendSeq(记录自己节点发送了多少msg),delivered(列表记录各个结点现在的序号),buffer(阻塞消息直到适合发送的事件)

- 每当结点自己要广播时,发送(自己结点编号,自己发送消息的序号,消息),并让自己发送消息的序号自增1
- 每当结点收到msg时,先将msg加入buffer,从buffer中寻找
msg[0] == sender && msg[1] == delivered[sender] + 1的,进行广播,并且把delivered[sender]自增
Causal broadcast algorithm
- 初始化同FIFO
- 当结点自己要发送时,比FIFO额外加上更新后的delivered数组
- 当节点接收msg时,比FIFO多一个判断delivered数组小(保证有因果关系的msg按顺序)

那么向量时钟如何比较并推断因果关系呢?利用下面的公式

Total order broadcast algorithms
比较难实现,一般可以考虑通过第三方协调服务实现或通过单节点统一管理
领导人方法:
- 所有结点想要广播必须发给领导,让领导按照FIFO来发
- 问题:领导宕机,重新选举很困难
参考文献
Lamport 逻辑时钟(Lamport Timestamp)和 Vector Clock 简单理解 | 沧海月明 (inlighting.org)
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!