effective C++ 第三版 第一章
本文最后更新于:2021年10月27日 凌晨
守则01:把C++看做一个语言的集合,而不是单一的语言
“C++ is a federation of languages”
早期的C++只是叫”C with classes”,但发展到今天已经成为一个多重泛型编程语言(Multi-paradigm programming language),它具有4种“子语言”:
- C
- 面向对象的C++
- 模板C++
- STL
高效的C++编程守则取决于你所使用的“子语言”
例如**:**
- 在C中,一般使用值传递 (Pass by value)
- 在**面向对象的C++和模板C++**中,使用常量引用传递 (Pass by const reference)更加高效
- 对于STL,因为迭代器是基于指针构造而成,直接使用值传递即可
守则02:尽量使用const, enum, inline, 减少宏变量#define的使用
或者说,尽量多用编译器,少用预处理器
“Prefer the compiler to the preprocessor”
C++提供的编译预处理功能主要有以下三种:
① 宏定义
② 文件包含
③条件编译
1 | |
在上面这个语句中,字符串’A’是不会被编译器看到的,而编译器看到的是’1.653’,这就会导致在调试过程中,编译器的错误信息只显示’1.653’而不是’A’,让你不知从何下手。
解决方法:定义全局常量
1 | |
使用全局常量还有一个好处:预处理器只会把每次对’A’的引用变成’1.653’而不管其是否已经存在,这就导致多次引用’A’会造成多个重复对象出现在目标代码中(Object code),造成资源浪费。
当定义或声明全局变量时,常数指针和类的常数需要另加考虑
- 对于指针
对于指针要把指针本身和它指向的数据都定义为const,例如
1 | |
(指向常量的常量指针)
在C++中可以更方便地使用std::string这样基于char*类型的推广,例如
1 | |
- 对于类的常数
声明为类的私有静态成员,这样既保证变量只能被这个类的对象接触到,又不会生成多个拷贝
1 | |
注意,因为此处是类的成员声明范围内,所以上面只是变量的声明和初始化,而并非定义,因此如果想获取变量的地址,需要在别处另加定义。这个定义不能有任何赋值语句,因为在类内已经规定为const:
1 | |
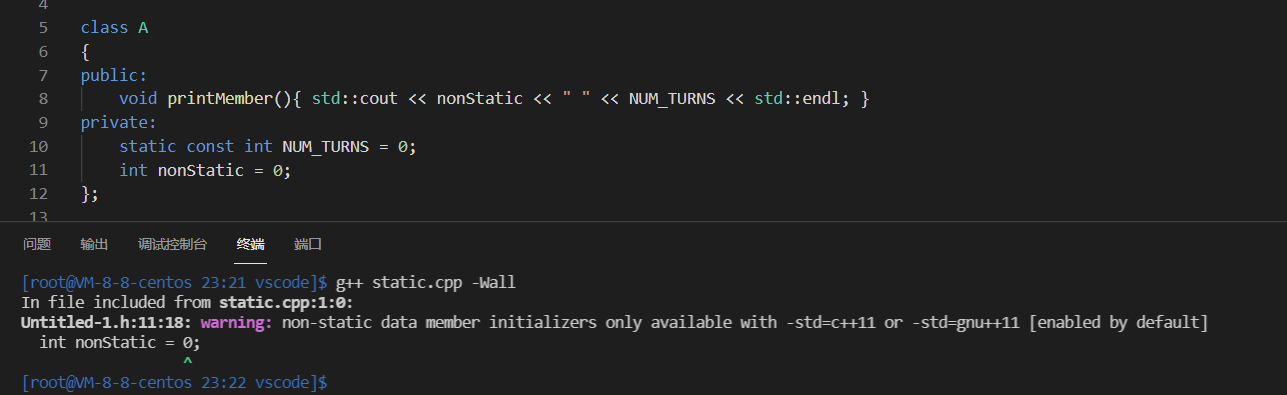
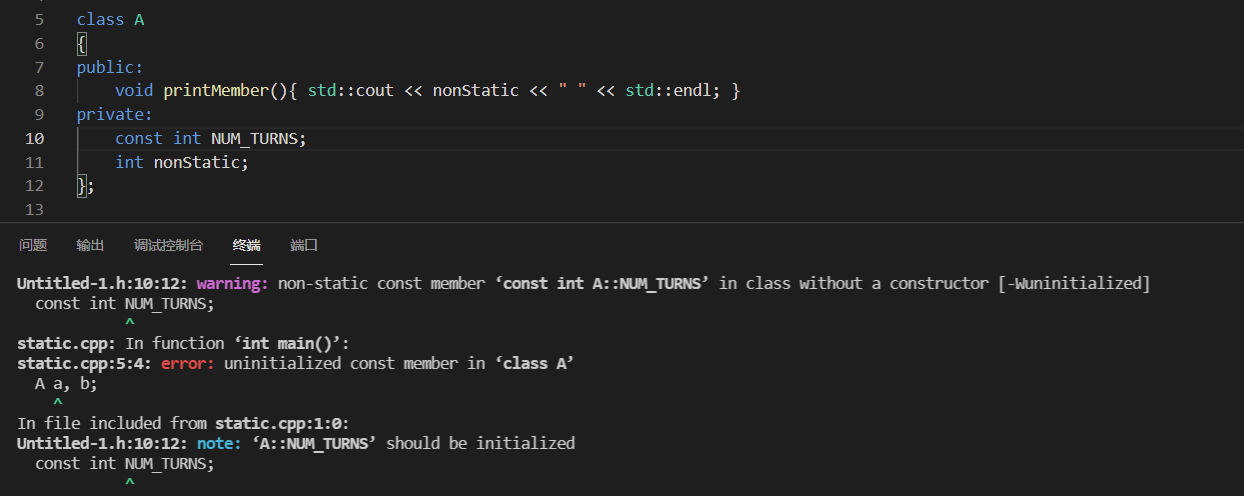
额外的补充:类内const推荐用static
细节可见(4)
static的const对象赋初值与否编译器都能通过
非static的const对象不允许赋初值
赋值会报错
error: non-static const member ‘const int A::NUM_TURNS’, can’t use default assignment operator
不赋值且无构造函数也会报错
error: non-static const member ‘const int A::NUM_TURNS’, can’t use default assignment operator
对于#define的宏函数,尽量使用inline修饰的函数来代替#define
C中经常会用形如#define max(a,b) ((a) > (b) ? (a) : (b))这样的宏而不是定义成函数,一方面为了代码编写简洁而另一方面,又不增加函数调用的开销。
为什么要加()呢,因为怕运算符优先级问题引起歧义,这在C中已是路人皆知的技巧。
但实际上这种手法捉襟见肘,缺陷很多,比如:
1 | |
虽然有点故意刁难的意思。
C++的inline完全规避了这种缺陷,可以改为inline函数:
1 | |
inline还有一个好处就是现代的编译器都比程序员聪明,你显式声明inline实际上最终不一定是inline,而有一些即使不声明inline也会被编译器优化成inline,这是C++的一大性能优化。
守则03: 尽可能使用const关键字
“Use const whenever possible”
- 指针与const:
记忆法: const在星号左边修饰数据,const在星号右边修饰指针
以及如下两个语句的功能是相同的,不需要对此产生困惑:
1 | |
- 迭代器与const
迭代器在功能上相当于指向某类型T的指针 T*
区分 const iterator 和 const_iterator
因此,如果想定义某迭代器指向一个常数,使用const iterator是不可以的,这样只相当于定义一个迭代器为一个常量(T* const),例如:(相当于指向常量的指针)
1 | |
解决方法,使用const_iterator:(相当于指针本身为常量)
1 | |
- 尽量使用const可以帮助调试
- 类的成员函数与const
- 成员函数的常量性(Constness)
- 在定义常量与非常量成员函数时,避免代码重复
既然两个版本的成员函数都要有,为什么又要避免重复?
其实在这里指的是函数的实现要避免重复。试想某函数既要检查边界范围,又要记录读取历史,还要检查数据完整性,这样的代码复制一遍,既不显得美观,又增加了代码维护的难度和编译时间。因此,我们可以使用非常量的函数来调用常量函数。(绝对不能是常量调用非常量版本)
1 | |
为了避免无限递归调用当前非常量的操作符,我们需要将(*this)转换为const Text&类型才能保证安全调用const的操作符,最后去掉const关键字(const_cast)再将其返回,巧妙避免了代码的大段复制。
守则04: 在使用前保证对象是初始化的
- 自有类型(built-in type)的初始化
C++的自有类型继承于C,因此不能保证此类型的变量在定义时被初始化。使用未初始化的数据可能会导致程序不正常运作,因此在定义变量的时候,需要对其进行初始化。
- 类的初始化
对于用户自定义的类,我们需要构造函数(constructor)来完成此类的初始化
C++规定,在进入构造函数之前,如果用户没有规定初始化过程,C++将自动调用各成员对应类型的默认构造函数。
这样一来,此构造函数就相当于先调用了C++的默认构造函数,又做了一次赋值操作覆盖掉了先前的结果,造成了浪费。
解决方法:使用**初始化列表(initialization list)**,C++就不必额外调用默认构造函数了。
某些初始化是语法必要的
例如在定义引用(reference)和常量(const)时,不将其初始化会导致编译器报错
1
2
3
4
5
6const int a; //报错,需要初始化!
int& b; //报错,需要初始化!
//现在对其进行初始化:
const int a = 3; //编译通过
int c = 3;
int& b = c; //编译通过!数据初始化的顺序
在继承关系中,基类(base class)总是先被初始化。
在同一类中,成员数据的==初始化顺序与其声明顺序是一致的==,而不是初始化列表的顺序。因此,为了代码一致性,要保证初始化列表的顺序与成员数据声明的顺序是一样的。
- 初始化非本地静态对象
编译单元(translation unit): 可以让编译器生成代码的基本单元,一般一个源代码文件就是一个编译单元。
非本地静态对象(non-local static object): 静态对象可以是在全局范围定义的变量,在名空间范围定义的变量,函数范围内定义为static的变量,类的范围内定义为static的变量,而除了函数中的静态对象是本地的,其他都是非本地的。
此外注意,静态对象存在于程序的开始到结束,所以它不是基于堆(heap)或者栈(stack)的。初始化的静态对象存在于.data中,未初始化的则存在于.bss中。
回到问题,现有以下服务器代码:
1 | |
又有某客户端:
1 | |
以上问题在于,定义对象client自动调用了Client类的构造函数,此时需要读取对象server的数据,但全局变量的不可控性让我们不能保证对象server在此时被读取时是初始化的。试想如果还有对象client1, client2等等不同的用户读写,我们不能保证当前server的数据是我们想要的。
解决方法: 将全局变量变为本地静态变量
使用一个函数,只用来定义一个本地静态变量并返回它的引用。==因为C++规定在本地范围(函数范围)内定义某静态对象时,当此函数被调用,该静态变量一定会被初始化。==(singleton模式)
1 | |
1 | |
第一章总结
- 视 C++ 为一个语言联邦(C、Object-Oriented C++、Template C++、STL)
- 宁可以编译器替换预处理器(尽量以
const、enum、inline替换#define) - 尽可能使用 const
- 确定对象被使用前已先被初始化(构造时赋值(copy 构造函数)比 default 构造后赋值(copy assignment)效率高)
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!